AI Free Basic Course | Lecture 25 | Building & Training CNN | Live Session
AI Free
Basic Course | Lecture 25 | Building & Training CNN | Live Session
Yesterday
we discussed about the convolutional Neural Network (CNN). We could not
understand, how the features map is formed when filter is applied on an image.
We studied
that convolutional Neural Network (CNN) is better than Artificial Neural
Network (ANN). Now we explain what features make Convolutional Neural Network
better than Artificial Neural Network (ANN).

Look at the
image of puzzle. We give the same puzzle to two different friends. One friend
is given the puzzle blocks after mixing it haphazardly and ask him to recognize
the image by watching each block of the puzzle. Other friend is given the same
parts of the puzzle in arranged form and ask him to recognize the image.
The second
friends start to watching the puzzle from upper left and glides eyes on the
image in slices and recognize the image at the end. During the process of
recognizing the image, he is watching the image in small pieces.
Second
friend will recognize the image more easily than the first friend.
Artificial
Neural Network works like the first friend in the example given above. We break
the image in pixels before giving it to the Artificial Neural Network like
blocks in the example.
Coevolutionary
Neural Network works like the second friend and recognizes the image by
applying filter on small part of it.
We take a
picture and view it with the help of a magnifying glass piece by piece. The
process of viewing the image piece by piece is called rendering. During the
rendering process it is our choice to move in any direction whether it is
diagonal, vertical or horizontal. The decision about the direction we make is
called filtration. We will place value of 1 in the direction in which we are
applying our filter.
During the
process of rendering the value of the filter is added with the value of the rendering
space and the added value is displayed as first digit on the feature map. Thus,
feature map is formed in this way.
In order to
understand this, we take an example. Suppose we have small pieces of tringle,
circle and square. We stain these shapes with the Stainer which allows only
passing of triangle shape from its holes. In the same filter works, it applied
vertically it will select only vertical lines including edges and different
shapes of the image.
As we
discussed earlier the image of cat or dog is not actually image of cat or dog
for the computer, image is a large matrix which contains number of numbers. If
we want to identify a logo from the given picture, we can apply binary
classification model to identify the logo. By making the convolutional model and
applying the sigmoid neuron at the end the model will tell whether it is logo
or not.
The
artificial neural network converts the image pixels in one dimensional layer
and take all these pixels as input. As the image size of amnist data comprising
28 x 28 pixels is converted into 784 one dimensional pixels. The problem with
this network is that as the size of image increases the parameters or
dimensions of the image would increase and would it difficult to process. In
order to deal with this problem, we use Coevolutionary Neural Network which
extracts features from image and the model learns with the less parameters. So,
we have computationally less expensive model in the form of coevolutionary
network.
We will see
the difference of computational power used by Artificial Neural Network and
Coevolutionary Neural Network during practicing the code in collab. We will see
how the number of parameters is reduced in Coevolutionary Neural Network as
compared to Artificial Neural Network.
Another
example is that in Artificial Neural Network, we divide the image by cutting
into strips vertically or horizontally during the process of converting it to 1
Dimensional layer. Process makes identification of image difficult for the
computer although it detects the image ultimately.
On the
other side in Coevolutionary Neural network inherently look the image more
clearly as the 2-Dimensional status of the image remain in intact and the model
detects the image easily. So convolutional Neural Network is inherently
superior in computer vision.

In the
image a kernel is moving over the image and a feature map as a result is
formed. It means that convolution process is being performed when the kernel or
filter is moving over the image frame by frame. During the process the kernel
or filter is detecting the features of the image like whether these are curved
or diagonal or straight lines and print the same on the feature map.
It works
like you have a map larger in size, you extract your desired location from it
and draw your map on the separate page and then pick the relevant information
from it.
To make it
more understandable we taken another example. Suppose you have a image in front
of you as a computer. During the process of convolution, first of all you see
it with the yellow glasses and select the parts of the image that look
prominent due to wearing the yellow glasses. After that, you see it with the
red glasses and select the parts of the image that look prominent due to
wearing the red glasses and so on. So every filter chooses the different features
from the image.
It means
when we form the convolution layer in convolution neural network, every
convolution neuron will act like yellow or red glasses and would detect
different features from the image.
So each
convolution neuron in the first layer will store separate features in it and
after combining these features will develop another new image and will pass it
to another layer.
The next
layer will scan it with another type of glasses and this layer now would have
more information and which will make it possible to detect such features from
the image that could not be detected from the image possibly. The function of
last layer is to decide whether it is desired information or not.

Above is an
architecture of Convolution Neural Network. There is input image upon which the
filter was applied and a feature map was formed as a result. Then we apply the
pooling technique over the feature map. Pooling is the process of extracting
the significant parts from the feature map. Suppose we are observing 2 x 2
image in a feature map and from these four values we pick the important value
and pass it to the next layer.
What we
actually are doing, we are picking the important information step by step to
make processing or computation easy. Initially we have 16 x 16 image which is
being gradually reduced. The information remains the same, but dimension reduce.
At the next
layer, the pooling process will pick the significant features and left behind
the nonsignificant features. At the end we will have an image having all
desired information with less dimensions.
At last, we
will take the fully connected neural network layer and pass the information to
it. As the fully connected neural network was not able to extract the features
so we passed the information after extracting the features with the help of
convolution Neural Network and pooling.
We know
that the number of neurons in fully connected neural network must be equal to
number of classes and activation function of soft max would be applied over the
layer of fully connected neural network.
Let us
summarize it. In convolution Network there are four type of layers.
1.
Input layer
2.
Convolution
layer which processes the filters.
3.
Max Pooling
layer which reduces the dimensions.
4.
Fully
Connected Layer which do the classification or regression.(Supervise Learning)
At the
output layer:
· if the problem is related to the binary
classification, we will apply single sigmoid and
· if the problem is related to multi class
classification, then we will apply Soft Max group.
· If the problem is related to regression, then we will
apply relu.
Every
neuron has two parts. First part do the linear calculation by multiplying the
weight with input and add bias. Second
part of neuron is activation function which can be relu or sigmoid or softmax.
So in
linear neuron, we do the linear calculation and give the out put without
applying the activation function.
Let us go
to the collab notebook:
Today we
will connect our collab notebook in a different way.
1.
We will
click the Reconnect button and will go for change runtime.





Today we
will apply CNN on amnist data to compare it with Fully Connected Network we
applied on the same in the previous lecture.


|
import matplotlib.pyplot as plt #
Number of digits to display n = 10 #
Create a figure to display the images plt.figure(figsize=(20, 4)) # Loop
through the first 'n' images for i in range(n):
#
Create a subplot within the figure
ax = plt.subplot(2, n, i + 1)
#
Display the original image
plt.imshow(X_test[i].reshape(28, 28))
# Set
colormap to grayscale
plt.gray()
# Hide
x-axis and y-axis labels and ticks
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False) # Show
the figure with the images plt.show() #
Close the figure plt.close() |
- Line
1: Imports the matplotlib.pyplot module.
- Line
2: Defines the variable n to store the number of digits to
display.
- Line
3: Creates a figure to display the images.
- Line
4: Starts a loop to iterate over the first n images in
the X_test array.
- Line
5: Creates a subplot within the figure for the current image.
- Line
6: Displays the original image in the subplot.
- Line
7: Sets the colormap to grayscale.
- Line
8: Hides the x-axis and y-axis labels and ticks.
- Line
9: Ends the loop.
- Line
10: Shows the figure with the images.
- Line
11: Closes the figure.



Now we are reshaping the data, in
artificial neural network we boke the images in pixels but in Convolution
Neural Network we gave the whole picture on which filleter is applied.
It reshapes the x_train and x_test tensors to have the shape (batch_size, height, width, channels), where channels is 1. This is the
"channel last" format that is used by the TensorFlow backend.
The x_train and x_test tensors are typically images, and the channels dimension
represents the number of color channels in the image. In this case, the images
are grayscale, so there is only one channel. What
if 1 is not given? It will assume the model in three colors as Red Green and
Blue.
The reshape() function takes a tensor as input and returns a new tensor with
the specified shape. The shape is a list of integers that specifies the number
of elements in each dimension of the tensor. In this case, the first dimension
of the shape is the batch size, which is the number of images in the dataset.
The second and third dimensions are the height and width of the images,
respectively. The fourth dimension is the number of channels, which is 1.

In the provided code, we are normalizing the pixel values of the image data in the X_train and X_test arrays to a
range between 0 and 1. This normalization step is another important
preprocessing technique often used when working with image data in machine
learning.
|
|
The idea behind this normalization is to scale the
pixel values so that they lie within the range [0, 1]. The original pixel
values usually span from 0 (black) to 255 (white) in grayscale images. By
dividing each pixel value by 255, you effectively rescale the values to be in
the range [0, 1], which is more suitable for many machine learning algorithms
and neural networks.

Normalizing the data helps in preventing issues
related to varying scales of input features. It can also improve the
convergence speed and stability of training processes, especially when using
optimization algorithms like gradient descent.
Keep in mind that normalization is a crucial step,
especially when dealing with neural networks, as it can have a significant
impact on the model's performance and training dynamics.
Processing the Target
variable
As we know that our variables are 10 and in our
target variable there can be any digit between 0 and 10. Now we have to convert our variables in the
form of 0 and 1 to make it understandable to the model. Now challenge is that
we have now 10 number of classes instead of 2 number of classes that were easy
to classify into 0 and 1 format. In order to overcome this challenge, first of
all have a glance of this pictorial representation.

Suppose we have a image that is 0 digit image. The
first column of the row against it will define it as vector 1 and the remaining
values would be 0. So in our target variable there would have 10 vectors for
every image one value out of which would be 1 . This location of the value
would tell about the identity of the digit.
For example it the location of 1 is under columns 2,
it means the image would be 2
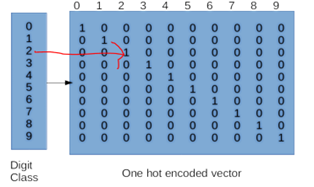
In order to have this type of classification we have imported the categorical module below.
It uses the to_categorical () function from the keras.utils module to convert
the labels from the y_train and y_test tensors into one-hot encoded vectors.

One-hot encoding is a technique used to represent categorical
data in a way that is compatible with machine learning algorithms. In this
case, the labels are categorical, because they represent the class of each
image. One-hot encoding converts each label into a vector of binary values,
where the index of the 1 value corresponds to the class of the image.
The to_categorical() function takes two arguments: the input tensor
and the number of classes. In this case, the number of classes is 10, because
there are 10 different classes of images in the dataset.
The output of the to_categorical() function is a tensor with the
same shape as the input tensor, but with an additional dimension for the class
labels. In this case, the output tensor will have the shape (batch_size, 10), where batch_size is the number of
images in the dataset.
The print() statements in your code will print the shapes of the x_train, y_train, x_test, and y_test tensors. The shapes
of the tensors will be updated to reflect the one-hot encoding of the labels.
The output of the print statements will display the shapes of your data
arrays after the one-hot encoding has been applied:
- x_train.shape should be (num_samples, height,
width, channels) as you reshaped it earlier.
- y_train.shape should be (num_samples, num_classes)
after one-hot encoding.
- x_test.shape should similarly have the shape (num_samples, height, width, channels) as x_train.
- y_test.shape should also have the shape (num_samples, num_classes) after one-hot encoding.
|
·
from keras.models import Sequential ·
from keras.layers.core import Dense ,Flatten ·
from
keras.layers.convolutional import Conv2D, MaxPooling2D
|
We are importing the
necessary modules from Keras to build a convolutional neural network (CNN)
model. Here's a breakdown of the imports:
1. Sequential: This is the basic
type of model in Keras, allowing you to build a linear stack of layers.
2. Dense: This is a fully
connected (dense) layer, where every neuron in the layer is connected to every
neuron in the previous and subsequent layers. You'll typically use this for the
final classification layer.
3. Flatten: This layer is used
to flatten the multi-dimensional data into a one-dimensional vector. It's often
used to transition from convolutional and pooling layers to fully connected
layers.
4. Conv2D: This is a 2D
convolutional layer, which applies convolutional operations to the input data.
You can specify the number of filters, kernel size, activation function, and
more.
5. MaxPooling2D: This layer
performs max pooling, which reduces the spatial dimensions of the data while
retaining the most important features. It helps with feature extraction and
dimensionality reduction.
With these modules imported, you can proceed to
build your CNN architecture using Keras. You'll define a Sequential model, add
convolutional, pooling, and dense layers, and then compile and train the model
using your data.
|
#
img_rows, img_cols, channels = 28, 28, 1 # 1 for greyscale images and 3 for
rgb images
#
classes=10 #
Define the dimensions of the input image img_rows,
img_cols, channels = 28, 28, 1 # 1 for greyscale images and 3 for rgb images
#
Define the number of filters for each layer of the CNN filters
= [6, 32, 80 ,120] # These are the number of
filters in each layer of the CNN
#
Define the number of classes for classification classes
= 10 # This is the number of
different categories that the CNN will classify images into
|
We are setting up various parameters and configurations
for a Convolutional Neural Network (CNN) architecture. Here's a breakdown of
what each part of the code is doing:
1. Image Dimensions:
·
img_rows and img_cols define the
dimensions of the input images. These are set to 28x28, which is common for
MNIST dataset-like images.
·
channels specifies the number of color channels in the
images. For grayscale images, this is 1, and for RGB images, this would be 3.
2. Number of Filters:
·
filters is a list that defines the number of filters for
each layer of the CNN. The first layer has 6 filters, the second has 32
filters, the third has 80 filters, and the fourth has 120 filters.
·
Filters in CNNs are responsible for extracting
different features from the input data. The number of filters determines the
complexity and capacity of the network to learn various features.
3. Number of Classes:
·
classes specifies the number of different categories (or
classes) that the CNN will classify images into. In this case, it's set to 10,
which could correspond to different digits in a digit recognition task, for
example.
These
parameter definitions are common when setting up a CNN architecture. The
specific values you've chosen for img_rows, img_cols, channels, filters, and classes will affect
the architecture and performance of your CNN model. You can use these
parameters when constructing your CNN layers using a framework like
TensorFlow/Keras.
|
#
Creating Model
model=Sequential()
#Sequential
is a container to store layers model.add(Conv2D(filters[0],(3,3),padding='same',\ activation='relu',input_shape=(img_rows,img_cols,
channels))) model.add(MaxPooling2D(pool_size=(2,2))) #For reducing image size #
(dim+pad-kernel)/2 (28 +3 -3)/2 = 14 model.add(Conv2D(filters[1],(2,2),padding='same', activation='relu')) model.add(MaxPooling2D(pool_size=(2,2))) # (dim+pad-kernel)/2
(14 +2 -2)/2 = 7 model.add(Conv2D(filters[2],(2,2),padding='same', activation='relu')) model.add(MaxPooling2D(pool_size=(2,2))) #
(dim+pad-kernel)/2 (7 +2 -2)/2 = 3 model.add(Conv2D(filters[3],(2,2),padding='same', activation='relu')) model.add(MaxPooling2D(pool_size=(2,2))) #
(dim+pad-kernel)/2 (3 +2 -2)/2 = 1 model.add(Flatten()) model.add(Dense(64,activation='relu')) model.add(Dense(classes,
activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
|
We have successfully
created a Convolutional Neural Network (CNN) model using Keras. Here's a
breakdown of the architecture and the purpose of each layer:
1. Sequential Model:
·
model=Sequential() initializes a sequential container to store layers
sequentially.
2. Convolutional and
MaxPooling Layers:
·
Conv2D(filters[0], (3,3), padding='same',
activation='relu', input_shape=(img_rows, img_cols, channels)) creates a convolutional
layer with 6 filters, a kernel size of (3,3), 'same' padding, ReLU activation,
and input shape defined by (img_rows, img_cols, channels).
·
MaxPooling2D(pool_size=(2,2)) adds a max-pooling layer
with a pool size of (2,2), reducing the image dimensions by half.
3. More Convolutional and
MaxPooling Layers:
·
Two more sets of convolutional and max-pooling
layers are added similarly. These layers help extract features and reduce
spatial dimensions further.
4. Flatten Layer:
·
Flatten() flattens the multi-dimensional output from the
previous layers into a one-dimensional vector.
5. Dense Layers:
·
Dense(64, activation='relu') adds a fully connected
layer with 64 neurons and ReLU activation.
·
Dense(classes, activation='softmax') adds the final fully
connected layer with neurons equal to the number of classes and a softmax
activation function for classification probabilities.
6. Model Compilation:
·
model.compile(loss='categorical_crossentropy',
optimizer='sgd', metrics=['accuracy']) compiles the model. The loss function is
categorical cross-entropy (suitable for multi-class classification), the
optimizer is stochastic gradient descent (SGD), and the metric for evaluation
is accuracy.
Our CNN architecture looks well-defined and ready for
training. You can use the model.fit() method
to train it on your training data (x_train and y_train). Remember to preprocess your data
appropriately before training.

|
Pooling
Layer |

Here is the
summary of processes we have passed through:


Now look at
the number of parameters in Fully Connected Neural Network and compare it with
the number of parameters in Coevolutionary Neural Network. You will see the
significant reduction.


It trains the CNN model on the x_train and y_train datasets and
evaluates the model on the x_test and y_test datasets.
The fit() function takes four arguments: the training data, the labels,
the validation split, the number of epochs, and the batch size. The validation
split is the fraction of the training data that is used for validation. The
number of epochs is the number of times the model will be trained on the entire
training data. The batch size is the number of images that are processed at a
time.
The evaluate() function takes two arguments: the test data and
the labels. The function returns the loss and accuracy of the model on the test
data.
The verbose argument controls the amount of output that is printed during
training and evaluation. A value of 0 will suppress all output, a value of 1
will print a summary of each epoch, and a value of 2 will print detailed
information about each epoch.


1. Import Libraries:
·
from sklearn.metrics import accuracy_score: Imports the accuracy_score function from scikit-learn, which is
used to calculate accuracy.
2. Predict and Evaluate:
·
y_pred_probs = model.predict(x_test, verbose=0): Predicts probabilities
for the test set using the trained model.
·
y_pred = np.where(y_pred_probs > 0.5, 1, 0): Converts the predicted
probabilities into binary predictions by thresholding at 0.5. If the predicted
probability is greater than 0.5, it's considered as class 1; otherwise, it's
class 0.
3. Calculate and Print
Accuracy:
· test_accuracy =
accuracy_score(y_pred, y_test): Calculates the accuracy between the predicted
labels (y_pred) and the true labels (y_test).
· print("\nTest
accuracy: {}".format(test_accuracy)): Prints the calculated test accuracy.
Please note that the
threshold value of 0.5 for binary classification might need to be adjusted
depending on your specific problem and dataset.
Also, ensure that x_test and y_test are properly
prepared and preprocessed before using them for prediction and evaluation. Make
sure that the shapes and formats of these arrays match the requirements of your
model.
Lastly, you've imported matplotlib.pyplot library, but you haven't used it in
this code snippet. If you intend to visualize something using matplotlib, you
might need to include additional code for that purpose.
|
#
Define a mask for selecting a range of indices (20 to 49) mask =
range(20, 50)
#
Select the first 20 samples from the test set for visualization X_valid
= x_test[20:40] actual_labels
= y_test[20:40]
#
Predict probabilities for the selected validation samples y_pred_probs_valid
= model.predict(X_valid) y_pred_valid
= np.where(y_pred_probs_valid > 0.5, 1, 0)
|
We are creating a mask to select a range of indices (20 to
49) and then using this mask to select a subset of the test set for
visualization and evaluation. The code you've provided seems correct for this
purpose. Here's a breakdown of what each part of the code does:
1. Define Mask:
·
mask = range(20, 50): Defines a mask using the range function to select indices from 20 to 49.
2. Select Validation
Samples:
·
X_valid = x_test[20:40]: Uses slicing to select the first 20 samples from
the test set (indices 20 to 39) for visualization.
3. Select Actual Labels:
·
actual_labels = y_test[20:40]: Selects the corresponding
actual labels for the selected validation samples.
4. Predict and Threshold:
·
y_pred_probs_valid = model.predict(X_valid): Predicts probabilities
for the selected validation samples.
·
y_pred_valid = np.where(y_pred_probs_valid >
0.5, 1, 0):
Converts the predicted probabilities into binary predictions using a threshold
of 0.5.
The next steps could
involve visualizing the selected samples along with their actual labels and
predicted labels for comparison. You might also want to calculate and display
other metrics to evaluate the performance of your model on this subset of the
test set.
|
# Set
up a figure to display images n = len(X_valid) plt.figure(figsize=(20, 4))
for i in range(n):
#
Display the original image
ax = plt.subplot(2, n, i + 1)
plt.imshow(X_valid[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
#
Display the predicted digit
predicted_digit = np.argmax(y_pred_probs_valid[i])
ax = plt.subplot(2, n, i + 1 + n)
plt.text(0.5, 0.5, str(predicted_digit),
fontsize=12, ha='center', va='center')
plt.axis('off')
# Show
the plotted images plt.show()
#
Close the plot plt.close()
|
The code
you've provided is for visualizing a subset of the validation samples along
with their predicted digits. This is a common way to visually assess how well
your model is performing. Here's a breakdown of the code:
1. Set Up Figure:
·
n = len(X_valid): n is set to the
number of samples in your validation subset.
·
plt.figure(figsize=(20, 4)): Sets up a figure with a
specified size to display the images.
2. Display Original
Images:
· A loop
iterates through the range of n.
· ax = plt.subplot(2, n,
i + 1):
Creates a subplot to display the original image.
· plt.imshow(X_valid[i].reshape(28,
28)):
Displays the original image, reshaped to 28x28.
· plt.gray(): Sets the colormap to grayscale.
· ax.get_xaxis().set_visible(False) and ax.get_yaxis().set_visible(False): Hides the axes for
better visualization.
3. Display Predicted
Digits:
· Another
loop iterates through the range of n.
· predicted_digit =
np.argmax(y_pred_probs_valid[i]): Determines the predicted digit by finding the
index of the maximum value in the predicted probabilities.
· ax = plt.subplot(2, n,
i + 1 + n):
Creates a subplot to display the predicted digit.
· plt.text(0.5, 0.5,
str(predicted_digit), fontsize=12, ha='center', va='center'): Displays the predicted
digit as text in the center of the subplot.
· plt.axis('off'): Turns off the axis for
this subplot.
4. Show and Close Plot:
· plt.show(): Displays the entire plot
with the original images and predicted digits.
· plt.close(): Closes the plot.
This code will help you
visualize how well your model is predicting the digits for a subset of
validation samples. The top row shows the original images, and the bottom row
displays the predicted digits.

A convolution layer is a fundamental component of
the CNN architecture that performs feature extraction, which typically consists
of a combination of linear and nonlinear operations, i.e., convolution
operation and activation function.

A convolution layer
plays a key role in CNN, which is composed of a stack of mathematical
operations, such as convolution, a specialized type of linear operation.

Pooling Layer. Similar to the Convolutional Layer, the Pooling layer is responsible
for reducing the spatial size of the Convolved Feature. This is to decrease the
computational power required to process the data through dimensionality
reduction


What is an activation function and why use
them?
The activation function
decides whether a neuron should be activated or not by calculating the weighted
sum and further adding bias to it. The purpose of the activation function is to
introduce non-linearity into the output of a neuron.
Explanation: We
know, the neural network has neurons that work in correspondence with weight, bias, and their respective activation
function. In a neural network, we would update the weights and biases of the
neurons on the basis of the error at the output. This process is known as back-propagation.
Activation functions make the back-propagation possible since the gradients are
supplied along with the error to update the weights and biases.
Why do we need Non-linear activation function?
A neural network without an
activation function is essentially just a linear regression model. The
activation function does the non-linear transformation to the input making it
capable to learn and perform more complex tasks.
What is an activation function and why use
them?
The activation function
decides whether a neuron should be activated or not by calculating the weighted
sum and further adding bias to it. The purpose of the activation function is to
introduce non-linearity into the output of a neuron.
Explanation: We
know, the neural network has neurons that work in correspondence with weight, bias, and their respective activation
function. In a neural network, we would update the weights and biases of the
neurons on the basis of the error at the output. This process is known as back-propagation.
Activation functions make the back-propagation possible since the gradients are
supplied along with the error to update the weights and biases.
Why do we need Non-linear activation function?
A neural network without an
activation function is essentially just a linear regression model. The
activation function does the non-linear transformation to the input making it
capable to learn and perform more complex tasks.



Comments
Post a Comment