Topic-4-Large Language Models, Claude, Bard & Stable Diffusion

|
|
· Bard has real time information
· Bard is free and no costing modal
defined yet.
· Bard has more mature information.
· Content is more authentic.
· All responses directly go to your
Gmail draft folder


Information by Bard is real time, it does not mean that real time
modal is trained by our click. It responded at our click. Same thing we are doing at IrfanGpt although this function of bard
ai was not known to me.
Another feature is that we can google the desired information. The question here arises, which information would we have on clicking the Google it
buttons.
Would it be before asking the query or after asking the query? You never know, at what time it was updated.
Difference between bard and ChatGPT was explained with the help of an example. Suppose you ask your servant to serve 5–6 guests in your absence. In case of ChatGPT, it would fail to serve if number of guests are exceeded.


CLAUD
Claude is a
next-generation AI assistant based on Anthropic’s research into training
helpful, honest, and harmless AI systems. Accessible through a chat interface and
API in our developer console, Claude is capable of a wide variety of
conversational and text processing tasks while maintaining a high degree of
reliability and predictability.
Claude can help with use cases including summarization, search, creative
and collaborative writing, Q&A, coding, and more. Early customers report
that Claude is much less likely to produce harmful outputs, easier to converse
with, and more steerable - so you can get your desired output with less effort.
Claude can also take direction on personality, tone, and behaviour

Generative AI
Generative AI
is a type of artificial intelligence technology that can produce various types
of content, including text, imagery, audio and synthetic
data.
Generative AI
at the most of the time are neural networks. Neural networks we studied in Deep
Learning.
Is there any relationship
between Machine Learning and Deep Learning?
Deep Learning
is sub set of Machine Learning.
There are
always two parts in Generative AI. First part is called Encoder and Second Part
is called Decoder.
What does
Encoder and Decoder Do
Encoder will
take input from you and converts it in computer understandable language.
Decoder will
take out put from computer and converts it in human understandable language.
The encoder will
take the input and make it into a representation, suppose you are creating a concept
of a car in the mind of a child. You can represent the car by describing its
structure or showing him the picture of the car. These both are types of
representation.
Some
presentations are easier to understand and some presentations are difficult
to understand.
Encoder
function is to represent human centric representation and Decoder function is to
present machine centric representation.
Generative
Models
Examples of Generative Models
- Autoencoders
- Naïve Bayes.
- Bayesian networks.
- Markov random fields.
- Hidden Markov Models (HMMs)
- Latent Dirichlet Allocation (LDA)
- Generative Adversarial Networks (GANs)
- Autoregressive Model.
Representations
Earlier it
was elaborated that Machine Learning needs numbers, and now I am saying that
Machine Learning needs Numeric Representation to function.
What is
Regression and Classification?
You predict
score in regression an in classification you predict label.
A famous generative model that is being used is called Transformer Neural Networks.
Transformer Neural
Networks also has two parts:
Encoder
Transformer Neural Networks
Decoder
Transformer Neural Networks
When both
types have been trained, we can use both separately. We can perform
discrimination AI through Encoder separately and can perform Generative AI
through Decoder.
It means
wherever you will see the Generative AI, it means they would be Decoder part of
Transformer.
The Primary Goal
of Artificial Intelligence is to teach the computer without programming.
Another goal is to reduce the human effort and increase the productivity.
As the human
memory and multithreading capacity is limited and conversely, computer has
unlimited memory and multithreading capacity. Humans get bored by performing
repetitive tasks, but computer can perform these tasks efficiently.
The difference between Regression and Classification is that Regression predicts score and
Classification predicts Labels.
GENERATIVE AI
Every
Generative modal has two parts:
· Encoding – Human centric to Machine Centric.
· Decoding-Machine Centric to Human Centric.
The famous
Generative modal that is being used nowadays is Transformal Neural
Network. Transformal Neural Network also
has two parts:

It means if
we have a Trans-formal Encoder that can convert human information to computer
understandable information, is that possible that we can use this Encoder in
Classification or Regression. Definitely, the computer would as an output will
recognize that incoming information is about dog or cat. It means the Encoder
can discriminate through converting human representation to machine
representation but cannot generate information.
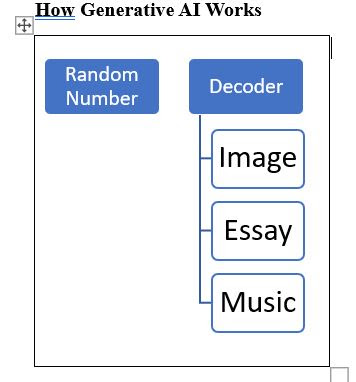
If we want to
create a generative modal, we will first train the modal and then with the help
of Decoder generate the information. As we know that Decoder converts Machine
representation to human representation so we give the Decoder a random number,
it would convert it either into an image or text.
So the
Generative Modals would be the Decoder part of the Transformer, as the Decoders are
best in converting Machine Language into Human representation.
WHAT IS LARGE
LANGUAGE MODAL
So LLM is
created by joining so many Decoders. However, by joining many Decoders alone
does not create LLM, you also have to train it my provision of large amount of
data available on Twitter, Wikipedia, news, etc. It sees the words patterns
available in this data to get train itself.
This helps the computer to make sense. For example, what comes after a dog can either “is
barking” or “is running”. As the “is barking” frequently used, so computer would
generate “is barking”. However, if ask computer to randomly choose from the
given ten words. The result would be different. So when we give the selection
strategy to the computer, it is like Computer Switching temperature strategy.
EMBEDDING FROM
TOKENS


STABLE
DIFFUSION
What is a Stable Diffusion?
Stable Diffusion is open-source artificial intelligence designed to generate images from natural text. This means that users
can make a request using natural language, and the AI will interpret and
generate an image that reflects the request.

In this
example, you replace the AC with the Modal and the air particles with image. The
modal acts on the pixels of the image as AC acts on the air particles. With the
passage of time, this slow processing of Modal will convert the good image to
bad image (Noise).
This
technique is being used in Traffic identification or satellite etc.
What if we
have to cool an Auditorium with the help of 2 Ton AC. The result will be
horrible as its not possible for the 2Ton AC to change the temperature of the
room. Similarly, mega pixel image create trouble for the AI modal as a lot of intensive
computing is required.
To deal with
this problem, we use latent diffuse Modal.
Stable /Latent Diffusion Models
(LDMs)





Comments
Post a Comment